
Bringing Browser-Based MFA SSO to the OpenStack CLI
Learn how a lightweight keystoneauth1 plugin brings your existing browser-based MFA and SSO to the OpenStack CLI, with no changes to any client tools.
Insights, updates, and stories from our team
Learn how a lightweight keystoneauth1 plugin brings your existing browser-based MFA and SSO to the OpenStack CLI, with no changes to any client tools.

Hyperscaler AI looks fast but hides long-term lock-in and rising costs. See how OpenStack and Kubernetes deliver GPU infrastructure you actually control.

Many AI clusters run at only 30–50% GPU utilization. Learn why GPUs sit idle and how Kubernetes, scheduling, and better infrastructure design can improve AI infrastructure efficiency.
Upgrading OpenStack to Epoxy? This field guide shows how to avoid version drift and outages with staged testing, blue-green control planes, health-gated cutovers, and audit-ready rollbacks.
If you’re running an older OpenStack release and considering a move to a more up to date one (e.g., Flamingo), the real conversation is about timing, risk, communication, and outcomes. This field guide looks at how to upgrade in a way that makes the result predictable, auditable, and worth the effort.
Most teams move when one or more of these conditions show up together:
If you’re already juggling regulatory deadlines or vendor end-of-life dates, upgrading on your terms reduces last-minute fire drills.

Your tenants and app teams should notice improved responsiveness and fewer rough edges in day-to-day work. Their tools, URLs, and workflows remain familiar. Leadership sees steadier reporting and a longer support runway.
A simple way to align executives and operators is to agree the “decision levers” up front:
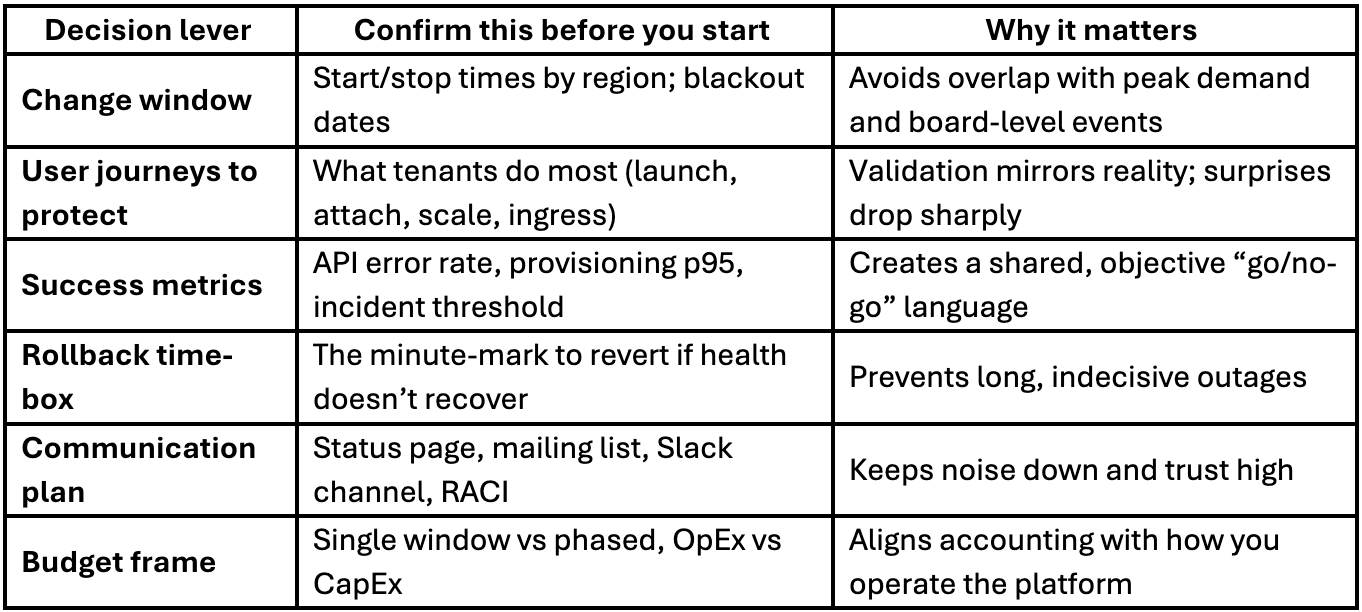
Most failed or painful upgrades share four patterns.
OpenStack is a constellation: Nova, Neutron, Keystone, Cinder, Glance, Placement, plus databases, message queues, and SDN. If one service races ahead while another lags, you inherit strange behavior and incompatible APIs. Solve this by pinning a “target constellation” up front: the OpenStack release, database version, RabbitMQ policy, OVN/OVS versions, and Linux kernel boundaries for hosts that need SR-IOV or DPDK.
Teams often tweak quotas, flavors, security groups, images, or scheduler traits to get features out the door. Those changes work… until the underlying defaults change. The cure is an inventory: export config deltas, tag images you rely on, enumerate traits and microversions used by automation, and write these into your plan.
Staging environments, blue-green control planes, and live migrations consume headroom. If your estate runs hot, the upgrade competes with your business. Reserve a modest buffer ahead of time (typically 10–15% of compute, more for GPU/SR-IOV aggregates) and time-box dual-run periods so cost and risk don’t balloon.
If you can’t see token issuance, scheduler throughput, queue depth, NB/SB raft health, and storage latency in one place, the cutover feels like flying at night. Put dashboards and alerts in place before you touch production, and agree on what “healthy” looks like numerically.
There isn’t a single “best” mechanism. Pick a pattern that aligns with your constraints on maintenance windows, capacity, and compliance.
You upgrade clustered components (Galera, RabbitMQ, OVN NB/SB raft) node by node while keeping quorum. API services roll forward with chart or package pins. This minimizes parallel infrastructure and avoids cross-cluster divergence.
Good fit when you have steady traffic, strict data lineage, and well-tuned clusters.
Key disciplines: respect Galera’s expand/contract phases for schema changes, keep NB/SB raft healthy during leader elections, and pace reboots so Neutron/OVN agents re-attach cleanly.
You stand up a “green” control plane that mirrors configuration, sync state that can be replicated (definitions in RabbitMQ, databases via tested backups), then swing API traffic via a load balancer VIP or DNS TTL reduction. Data planes like OVN and Galera typically remain single-homed and are upgraded in place to prevent split-brain.
Good fit when you want a dress rehearsal with live traffic and the ability to flip back quickly.
Key disciplines: federate and drain queues before cutover, keep microversions pinned during the window, and define a short roll-back time-box so you never hover in uncertainty.
When you’re several releases behind, you test each “hop” end-to-end in staging (including expand/contract DB steps), then execute a compressed version in production with pre-approved windows. You still use rolling and/or blue-green within each hop.
Good fit when you value momentum and want to exit end-of-life territory quickly without skipping validation.
Key disciplines: freeze change outside the program, keep automation and client tools pinned to compatible microversions until the final hop, and communicate clearly with tenants about new behaviors.
Your platform can live in more than one place, and the upgrade approach adapts accordingly.

Many organizations run a blend - validate in public, operate most steady systems in hosted, keep regulated workloads on-premise. The upgrade playbook remains consistent, which lowers cognitive load for teams.
Expect three cost drivers during an upgrade program:
👉 Temporary capacity: Staging and blue-green activity consume headroom. Plan a modest buffer and keep dual-run periods short. The fastest way to overspend is to extend dress rehearsals indefinitely.
👉 People time: Staging parity, test scripting, and runbook updates require concentrated effort for a few weeks. The payoff is fewer incidents later and quicker future upgrades.
👉 Communication and audit: Briefings, sign-offs, and compliance packages take real time. Consolidate artifacts into a small “evidence bundle”: change tickets, test results, dashboard screenshots, and backup logs.
With those accounted for, the upgrade becomes a bounded project rather than a creeping operational burden.
If your organization runs Atmosphere, you already have repeatable deployments, usage telemetry, and access to engineers around the clock in Hosted or On-Premise models. Upgrades follow the patterns above, with OpenStack-Helm for consistent rollouts, near-real-time usage insights during dual-run periods, and a familiar operational cadence across Public Cloud, Hosted, and On-Premise. The intent is to reduce friction while keeping you in control of timing, windows, and validation.
If you’re ready to think about an upgrade, talk to us, and we’ll share a clean starting point you can adapt to your operating model.
Choose from Atmosphere Cloud, Hosted, or On-Premise.
Simplify your cloud operations with our intuitive dashboard.
Run it yourself, tap our expert support, or opt for full remote operations.
Leverage Terraform, Ansible or APIs directly powered by OpenStack & Kubernetes